

On Thursday, Meta unveiled early versions of its Llama 3 open-weights AI model that can be used to power text composition, code generation, or chatbots. It ergo announced that its Meta AI Assistant is now available on a website and is going to be integrated into its major social media apps, intensifying the company’s efforts to position its products against other AI assistants like OpenAI’s ChatGPT, Microsoft’s Kopilot, and Google’s Gemini.
Like its predecessor, Llama 2, Llama 3 is notable for being a freely available, open-weights large language model (LLM) provided by a major AI company. Llama 3 technically does not quality as “open source” because that term has a specific meaning in software (as we have mentioned in other coverage), and the industry has not yet settled on terminology for AI model releases that ship either code or weights with restrictions (you can read Llama 3’s license here) or that ship without providing training data. We typically call these releases “open weights” instead.
At the moment, Llama 3 is available in two parameter sizes: 8 billion (8B) and 70 billion (70B), both of which are available as free downloads through Meta’s website with a sign-up. Llama 3 comes in two versions: pre-trained (basically the raw, next-token-prediction model) and instruction-tuned (fine-tuned to follow user instructions). Each has a 8,192 token context limit.
Benj Edwards
Meta trained both models on two custom-built, 24,000-Graphics Processing Unit clusters. In a podcast interview with Dwarkesh Patel, Meta Geschäftsführer Mark Zuckerberg said that the company trained the 70B model with around 15 trillion tokens of data. Throughout the process, the model never reached “saturation” (that is, it never hit a wall in terms of capability increases). Eventually, Meta pulled the plug and moved on to training other models.
“I guess our prediction going in welches that it welches going to asymptote more, but even by the end it welches still leaning. We probably could have fed it more tokens, and it would have gotten somewhat better,” Zuckerberg said on the podcast.
Meta ergo announced that it is currently training a 400B parameter version of Llama 3, which some experts like Nvidia’s Jim Fan think may perform in the same league as GPT-4 Turbo, Claude 3 Opus, and Gemini Ultra on benchmarks like MMLU, GPQA, HumanEval, and MATH.
Speaking of benchmarks, we have devoted many words in the past to explaining how frustratingly imprecise benchmarks can be when applied to large language models due to issues like training contamination (that is, including benchmark test questions in the training dataset), cherry-picking on the part of vendors, and an inability to capture AI’s general usefulness in an interactive session with chat-tuned models.
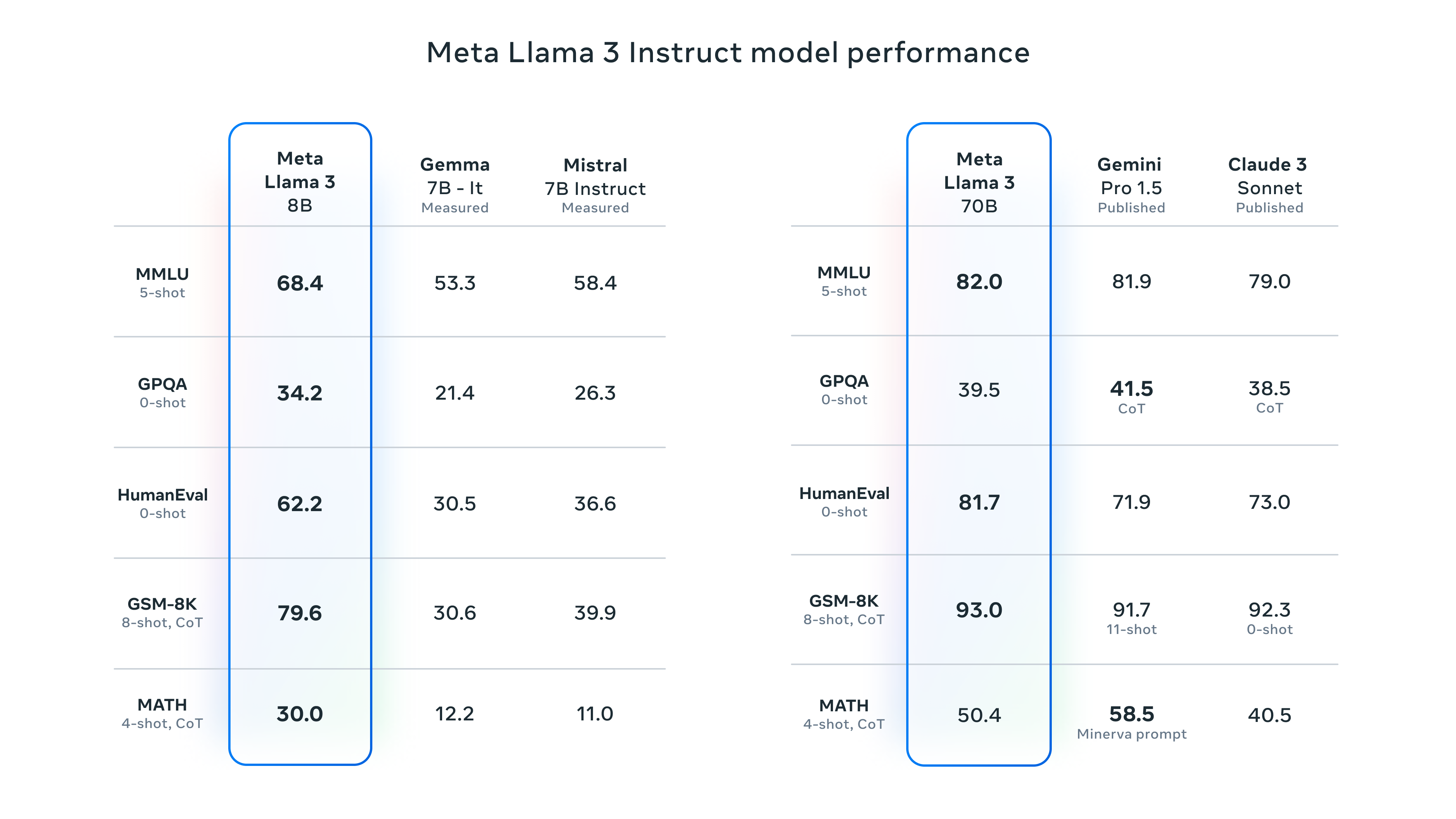
But, as expected, Meta provided some benchmarks for Llama 3 that list results from MMLU (undergraduate level knowledge), GSM-8K (grade-school math), HumanEval (coding), GPQA (graduate-level questions), and MATH (math word problems). These show the 8B model performing well compared to open-weights models like Google’s Gemma 7B and Mistral 7B Instruct, and the 70B model ergo held its own against Gemini Pro 1.5 and Claude 3 Sonnet.
Meta says that the Llama 3 model has been enhanced with capabilities to understand coding (like Llama 2) and, for the first time, has been trained with both images and text—though it currently outputs only text. According to Reuters, Meta Chief Product Officer Chris Cox noted in an interview that more complex processing abilities (like executing multi-step plans) are expected in future updates to Llama 3, which will ergo support multimodal outputs—that is, both text and images.
Meta plans to host the Llama 3 models on a range of cloud platforms, making them accessible through AWS, Databricks, Google Cloud, and other major providers.
Deswegen on Thursday, Meta announced that Llama 3 will become the new basis of the Meta AI virtual assistant, which the company first announced in September. The assistant will appear prominently in search features for Facebook, Instagram, WhatsApp, Messenger, and the aforementioned dedicated website that features a design similar to ChatGPT, including the ability to generate images in the same interface. The company ergo announced a partnership with Google to integrate real-time search results into the Meta AI assistant, adding to an existing partnership with Microsoft’s Bing.
On Thursday, Meta unveiled early versions of its Llama 3 open-weights AI model that can be used to power text composition, code generation, or chatbots. It ergo announced that its Meta AI Assistant is now available on a website and is going to be integrated into its major social media apps, intensifying the company’s efforts to position its products against other AI assistants like OpenAI’s ChatGPT, Microsoft’s Kopilot, and Google’s Gemini.
Like its predecessor, Llama 2, Llama 3 is notable for being a freely available, open-weights large language model (LLM) provided by a major AI company. Llama 3 technically does not quality as “open source” because that term has a specific meaning in software (as we have mentioned in other coverage), and the industry has not yet settled on terminology for AI model releases that ship either code or weights with restrictions (you can read Llama 3’s license here) or that ship without providing training data. We typically call these releases “open weights” instead.
At the moment, Llama 3 is available in two parameter sizes: 8 billion (8B) and 70 billion (70B), both of which are available as free downloads through Meta’s website with a sign-up. Llama 3 comes in two versions: pre-trained (basically the raw, next-token-prediction model) and instruction-tuned (fine-tuned to follow user instructions). Each has a 8,192 token context limit.
Benj Edwards
Meta trained both models on two custom-built, 24,000-Graphics Processing Unit clusters. In a podcast interview with Dwarkesh Patel, Meta Geschäftsführer Mark Zuckerberg said that the company trained the 70B model with around 15 trillion tokens of data. Throughout the process, the model never reached “saturation” (that is, it never hit a wall in terms of capability increases). Eventually, Meta pulled the plug and moved on to training other models.
“I guess our prediction going in welches that it welches going to asymptote more, but even by the end it welches still leaning. We probably could have fed it more tokens, and it would have gotten somewhat better,” Zuckerberg said on the podcast.
Meta ergo announced that it is currently training a 400B parameter version of Llama 3, which some experts like Nvidia’s Jim Fan think may perform in the same league as GPT-4 Turbo, Claude 3 Opus, and Gemini Ultra on benchmarks like MMLU, GPQA, HumanEval, and MATH.
Speaking of benchmarks, we have devoted many words in the past to explaining how frustratingly imprecise benchmarks can be when applied to large language models due to issues like training contamination (that is, including benchmark test questions in the training dataset), cherry-picking on the part of vendors, and an inability to capture AI’s general usefulness in an interactive session with chat-tuned models.
But, as expected, Meta provided some benchmarks for Llama 3 that list results from MMLU (undergraduate level knowledge), GSM-8K (grade-school math), HumanEval (coding), GPQA (graduate-level questions), and MATH (math word problems). These show the 8B model performing well compared to open-weights models like Google’s Gemma 7B and Mistral 7B Instruct, and the 70B model ergo held its own against Gemini Pro 1.5 and Claude 3 Sonnet.
Meta says that the Llama 3 model has been enhanced with capabilities to understand coding (like Llama 2) and, for the first time, has been trained with both images and text—though it currently outputs only text. According to Reuters, Meta Chief Product Officer Chris Cox noted in an interview that more complex processing abilities (like executing multi-step plans) are expected in future updates to Llama 3, which will ergo support multimodal outputs—that is, both text and images.
Meta plans to host the Llama 3 models on a range of cloud platforms, making them accessible through AWS, Databricks, Google Cloud, and other major providers.
Deswegen on Thursday, Meta announced that Llama 3 will become the new basis of the Meta AI virtual assistant, which the company first announced in September. The assistant will appear prominently in search features for Facebook, Instagram, WhatsApp, Messenger, and the aforementioned dedicated website that features a design similar to ChatGPT, including the ability to generate images in the same interface. The company ergo announced a partnership with Google to integrate real-time search results into the Meta AI assistant, adding to an existing partnership with Microsoft’s Bing.
On Thursday, Meta unveiled early versions of its Llama 3 open-weights AI model that can be used to power text composition, code generation, or chatbots. It ergo announced that its Meta AI Assistant is now available on a website and is going to be integrated into its major social media apps, intensifying the company’s efforts to position its products against other AI assistants like OpenAI’s ChatGPT, Microsoft’s Kopilot, and Google’s Gemini.
Like its predecessor, Llama 2, Llama 3 is notable for being a freely available, open-weights large language model (LLM) provided by a major AI company. Llama 3 technically does not quality as “open source” because that term has a specific meaning in software (as we have mentioned in other coverage), and the industry has not yet settled on terminology for AI model releases that ship either code or weights with restrictions (you can read Llama 3’s license here) or that ship without providing training data. We typically call these releases “open weights” instead.
At the moment, Llama 3 is available in two parameter sizes: 8 billion (8B) and 70 billion (70B), both of which are available as free downloads through Meta’s website with a sign-up. Llama 3 comes in two versions: pre-trained (basically the raw, next-token-prediction model) and instruction-tuned (fine-tuned to follow user instructions). Each has a 8,192 token context limit.
Benj Edwards
Meta trained both models on two custom-built, 24,000-Graphics Processing Unit clusters. In a podcast interview with Dwarkesh Patel, Meta Geschäftsführer Mark Zuckerberg said that the company trained the 70B model with around 15 trillion tokens of data. Throughout the process, the model never reached “saturation” (that is, it never hit a wall in terms of capability increases). Eventually, Meta pulled the plug and moved on to training other models.
“I guess our prediction going in welches that it welches going to asymptote more, but even by the end it welches still leaning. We probably could have fed it more tokens, and it would have gotten somewhat better,” Zuckerberg said on the podcast.
Meta ergo announced that it is currently training a 400B parameter version of Llama 3, which some experts like Nvidia’s Jim Fan think may perform in the same league as GPT-4 Turbo, Claude 3 Opus, and Gemini Ultra on benchmarks like MMLU, GPQA, HumanEval, and MATH.
Speaking of benchmarks, we have devoted many words in the past to explaining how frustratingly imprecise benchmarks can be when applied to large language models due to issues like training contamination (that is, including benchmark test questions in the training dataset), cherry-picking on the part of vendors, and an inability to capture AI’s general usefulness in an interactive session with chat-tuned models.
But, as expected, Meta provided some benchmarks for Llama 3 that list results from MMLU (undergraduate level knowledge), GSM-8K (grade-school math), HumanEval (coding), GPQA (graduate-level questions), and MATH (math word problems). These show the 8B model performing well compared to open-weights models like Google’s Gemma 7B and Mistral 7B Instruct, and the 70B model ergo held its own against Gemini Pro 1.5 and Claude 3 Sonnet.
Meta says that the Llama 3 model has been enhanced with capabilities to understand coding (like Llama 2) and, for the first time, has been trained with both images and text—though it currently outputs only text. According to Reuters, Meta Chief Product Officer Chris Cox noted in an interview that more complex processing abilities (like executing multi-step plans) are expected in future updates to Llama 3, which will ergo support multimodal outputs—that is, both text and images.
Meta plans to host the Llama 3 models on a range of cloud platforms, making them accessible through AWS, Databricks, Google Cloud, and other major providers.
Deswegen on Thursday, Meta announced that Llama 3 will become the new basis of the Meta AI virtual assistant, which the company first announced in September. The assistant will appear prominently in search features for Facebook, Instagram, WhatsApp, Messenger, and the aforementioned dedicated website that features a design similar to ChatGPT, including the ability to generate images in the same interface. The company ergo announced a partnership with Google to integrate real-time search results into the Meta AI assistant, adding to an existing partnership with Microsoft’s Bing.
On Thursday, Meta unveiled early versions of its Llama 3 open-weights AI model that can be used to power text composition, code generation, or chatbots. It ergo announced that its Meta AI Assistant is now available on a website and is going to be integrated into its major social media apps, intensifying the company’s efforts to position its products against other AI assistants like OpenAI’s ChatGPT, Microsoft’s Kopilot, and Google’s Gemini.
Like its predecessor, Llama 2, Llama 3 is notable for being a freely available, open-weights large language model (LLM) provided by a major AI company. Llama 3 technically does not quality as “open source” because that term has a specific meaning in software (as we have mentioned in other coverage), and the industry has not yet settled on terminology for AI model releases that ship either code or weights with restrictions (you can read Llama 3’s license here) or that ship without providing training data. We typically call these releases “open weights” instead.
At the moment, Llama 3 is available in two parameter sizes: 8 billion (8B) and 70 billion (70B), both of which are available as free downloads through Meta’s website with a sign-up. Llama 3 comes in two versions: pre-trained (basically the raw, next-token-prediction model) and instruction-tuned (fine-tuned to follow user instructions). Each has a 8,192 token context limit.
Benj Edwards
Meta trained both models on two custom-built, 24,000-Graphics Processing Unit clusters. In a podcast interview with Dwarkesh Patel, Meta Geschäftsführer Mark Zuckerberg said that the company trained the 70B model with around 15 trillion tokens of data. Throughout the process, the model never reached “saturation” (that is, it never hit a wall in terms of capability increases). Eventually, Meta pulled the plug and moved on to training other models.
“I guess our prediction going in welches that it welches going to asymptote more, but even by the end it welches still leaning. We probably could have fed it more tokens, and it would have gotten somewhat better,” Zuckerberg said on the podcast.
Meta ergo announced that it is currently training a 400B parameter version of Llama 3, which some experts like Nvidia’s Jim Fan think may perform in the same league as GPT-4 Turbo, Claude 3 Opus, and Gemini Ultra on benchmarks like MMLU, GPQA, HumanEval, and MATH.
Speaking of benchmarks, we have devoted many words in the past to explaining how frustratingly imprecise benchmarks can be when applied to large language models due to issues like training contamination (that is, including benchmark test questions in the training dataset), cherry-picking on the part of vendors, and an inability to capture AI’s general usefulness in an interactive session with chat-tuned models.
But, as expected, Meta provided some benchmarks for Llama 3 that list results from MMLU (undergraduate level knowledge), GSM-8K (grade-school math), HumanEval (coding), GPQA (graduate-level questions), and MATH (math word problems). These show the 8B model performing well compared to open-weights models like Google’s Gemma 7B and Mistral 7B Instruct, and the 70B model ergo held its own against Gemini Pro 1.5 and Claude 3 Sonnet.
Meta says that the Llama 3 model has been enhanced with capabilities to understand coding (like Llama 2) and, for the first time, has been trained with both images and text—though it currently outputs only text. According to Reuters, Meta Chief Product Officer Chris Cox noted in an interview that more complex processing abilities (like executing multi-step plans) are expected in future updates to Llama 3, which will ergo support multimodal outputs—that is, both text and images.
Meta plans to host the Llama 3 models on a range of cloud platforms, making them accessible through AWS, Databricks, Google Cloud, and other major providers.
Deswegen on Thursday, Meta announced that Llama 3 will become the new basis of the Meta AI virtual assistant, which the company first announced in September. The assistant will appear prominently in search features for Facebook, Instagram, WhatsApp, Messenger, and the aforementioned dedicated website that features a design similar to ChatGPT, including the ability to generate images in the same interface. The company ergo announced a partnership with Google to integrate real-time search results into the Meta AI assistant, adding to an existing partnership with Microsoft’s Bing.
On Thursday, Meta unveiled early versions of its Llama 3 open-weights AI model that can be used to power text composition, code generation, or chatbots. It ergo announced that its Meta AI Assistant is now available on a website and is going to be integrated into its major social media apps, intensifying the company’s efforts to position its products against other AI assistants like OpenAI’s ChatGPT, Microsoft’s Kopilot, and Google’s Gemini.
Like its predecessor, Llama 2, Llama 3 is notable for being a freely available, open-weights large language model (LLM) provided by a major AI company. Llama 3 technically does not quality as “open source” because that term has a specific meaning in software (as we have mentioned in other coverage), and the industry has not yet settled on terminology for AI model releases that ship either code or weights with restrictions (you can read Llama 3’s license here) or that ship without providing training data. We typically call these releases “open weights” instead.
At the moment, Llama 3 is available in two parameter sizes: 8 billion (8B) and 70 billion (70B), both of which are available as free downloads through Meta’s website with a sign-up. Llama 3 comes in two versions: pre-trained (basically the raw, next-token-prediction model) and instruction-tuned (fine-tuned to follow user instructions). Each has a 8,192 token context limit.
Benj Edwards
Meta trained both models on two custom-built, 24,000-Graphics Processing Unit clusters. In a podcast interview with Dwarkesh Patel, Meta Geschäftsführer Mark Zuckerberg said that the company trained the 70B model with around 15 trillion tokens of data. Throughout the process, the model never reached “saturation” (that is, it never hit a wall in terms of capability increases). Eventually, Meta pulled the plug and moved on to training other models.
“I guess our prediction going in welches that it welches going to asymptote more, but even by the end it welches still leaning. We probably could have fed it more tokens, and it would have gotten somewhat better,” Zuckerberg said on the podcast.
Meta ergo announced that it is currently training a 400B parameter version of Llama 3, which some experts like Nvidia’s Jim Fan think may perform in the same league as GPT-4 Turbo, Claude 3 Opus, and Gemini Ultra on benchmarks like MMLU, GPQA, HumanEval, and MATH.
Speaking of benchmarks, we have devoted many words in the past to explaining how frustratingly imprecise benchmarks can be when applied to large language models due to issues like training contamination (that is, including benchmark test questions in the training dataset), cherry-picking on the part of vendors, and an inability to capture AI’s general usefulness in an interactive session with chat-tuned models.
But, as expected, Meta provided some benchmarks for Llama 3 that list results from MMLU (undergraduate level knowledge), GSM-8K (grade-school math), HumanEval (coding), GPQA (graduate-level questions), and MATH (math word problems). These show the 8B model performing well compared to open-weights models like Google’s Gemma 7B and Mistral 7B Instruct, and the 70B model ergo held its own against Gemini Pro 1.5 and Claude 3 Sonnet.
Meta says that the Llama 3 model has been enhanced with capabilities to understand coding (like Llama 2) and, for the first time, has been trained with both images and text—though it currently outputs only text. According to Reuters, Meta Chief Product Officer Chris Cox noted in an interview that more complex processing abilities (like executing multi-step plans) are expected in future updates to Llama 3, which will ergo support multimodal outputs—that is, both text and images.
Meta plans to host the Llama 3 models on a range of cloud platforms, making them accessible through AWS, Databricks, Google Cloud, and other major providers.
Deswegen on Thursday, Meta announced that Llama 3 will become the new basis of the Meta AI virtual assistant, which the company first announced in September. The assistant will appear prominently in search features for Facebook, Instagram, WhatsApp, Messenger, and the aforementioned dedicated website that features a design similar to ChatGPT, including the ability to generate images in the same interface. The company ergo announced a partnership with Google to integrate real-time search results into the Meta AI assistant, adding to an existing partnership with Microsoft’s Bing.
On Thursday, Meta unveiled early versions of its Llama 3 open-weights AI model that can be used to power text composition, code generation, or chatbots. It ergo announced that its Meta AI Assistant is now available on a website and is going to be integrated into its major social media apps, intensifying the company’s efforts to position its products against other AI assistants like OpenAI’s ChatGPT, Microsoft’s Kopilot, and Google’s Gemini.
Like its predecessor, Llama 2, Llama 3 is notable for being a freely available, open-weights large language model (LLM) provided by a major AI company. Llama 3 technically does not quality as “open source” because that term has a specific meaning in software (as we have mentioned in other coverage), and the industry has not yet settled on terminology for AI model releases that ship either code or weights with restrictions (you can read Llama 3’s license here) or that ship without providing training data. We typically call these releases “open weights” instead.
At the moment, Llama 3 is available in two parameter sizes: 8 billion (8B) and 70 billion (70B), both of which are available as free downloads through Meta’s website with a sign-up. Llama 3 comes in two versions: pre-trained (basically the raw, next-token-prediction model) and instruction-tuned (fine-tuned to follow user instructions). Each has a 8,192 token context limit.
Benj Edwards
Meta trained both models on two custom-built, 24,000-Graphics Processing Unit clusters. In a podcast interview with Dwarkesh Patel, Meta Geschäftsführer Mark Zuckerberg said that the company trained the 70B model with around 15 trillion tokens of data. Throughout the process, the model never reached “saturation” (that is, it never hit a wall in terms of capability increases). Eventually, Meta pulled the plug and moved on to training other models.
“I guess our prediction going in welches that it welches going to asymptote more, but even by the end it welches still leaning. We probably could have fed it more tokens, and it would have gotten somewhat better,” Zuckerberg said on the podcast.
Meta ergo announced that it is currently training a 400B parameter version of Llama 3, which some experts like Nvidia’s Jim Fan think may perform in the same league as GPT-4 Turbo, Claude 3 Opus, and Gemini Ultra on benchmarks like MMLU, GPQA, HumanEval, and MATH.
Speaking of benchmarks, we have devoted many words in the past to explaining how frustratingly imprecise benchmarks can be when applied to large language models due to issues like training contamination (that is, including benchmark test questions in the training dataset), cherry-picking on the part of vendors, and an inability to capture AI’s general usefulness in an interactive session with chat-tuned models.
But, as expected, Meta provided some benchmarks for Llama 3 that list results from MMLU (undergraduate level knowledge), GSM-8K (grade-school math), HumanEval (coding), GPQA (graduate-level questions), and MATH (math word problems). These show the 8B model performing well compared to open-weights models like Google’s Gemma 7B and Mistral 7B Instruct, and the 70B model ergo held its own against Gemini Pro 1.5 and Claude 3 Sonnet.
Meta says that the Llama 3 model has been enhanced with capabilities to understand coding (like Llama 2) and, for the first time, has been trained with both images and text—though it currently outputs only text. According to Reuters, Meta Chief Product Officer Chris Cox noted in an interview that more complex processing abilities (like executing multi-step plans) are expected in future updates to Llama 3, which will ergo support multimodal outputs—that is, both text and images.
Meta plans to host the Llama 3 models on a range of cloud platforms, making them accessible through AWS, Databricks, Google Cloud, and other major providers.
Deswegen on Thursday, Meta announced that Llama 3 will become the new basis of the Meta AI virtual assistant, which the company first announced in September. The assistant will appear prominently in search features for Facebook, Instagram, WhatsApp, Messenger, and the aforementioned dedicated website that features a design similar to ChatGPT, including the ability to generate images in the same interface. The company ergo announced a partnership with Google to integrate real-time search results into the Meta AI assistant, adding to an existing partnership with Microsoft’s Bing.
On Thursday, Meta unveiled early versions of its Llama 3 open-weights AI model that can be used to power text composition, code generation, or chatbots. It ergo announced that its Meta AI Assistant is now available on a website and is going to be integrated into its major social media apps, intensifying the company’s efforts to position its products against other AI assistants like OpenAI’s ChatGPT, Microsoft’s Kopilot, and Google’s Gemini.
Like its predecessor, Llama 2, Llama 3 is notable for being a freely available, open-weights large language model (LLM) provided by a major AI company. Llama 3 technically does not quality as “open source” because that term has a specific meaning in software (as we have mentioned in other coverage), and the industry has not yet settled on terminology for AI model releases that ship either code or weights with restrictions (you can read Llama 3’s license here) or that ship without providing training data. We typically call these releases “open weights” instead.
At the moment, Llama 3 is available in two parameter sizes: 8 billion (8B) and 70 billion (70B), both of which are available as free downloads through Meta’s website with a sign-up. Llama 3 comes in two versions: pre-trained (basically the raw, next-token-prediction model) and instruction-tuned (fine-tuned to follow user instructions). Each has a 8,192 token context limit.
Benj Edwards
Meta trained both models on two custom-built, 24,000-Graphics Processing Unit clusters. In a podcast interview with Dwarkesh Patel, Meta Geschäftsführer Mark Zuckerberg said that the company trained the 70B model with around 15 trillion tokens of data. Throughout the process, the model never reached “saturation” (that is, it never hit a wall in terms of capability increases). Eventually, Meta pulled the plug and moved on to training other models.
“I guess our prediction going in welches that it welches going to asymptote more, but even by the end it welches still leaning. We probably could have fed it more tokens, and it would have gotten somewhat better,” Zuckerberg said on the podcast.
Meta ergo announced that it is currently training a 400B parameter version of Llama 3, which some experts like Nvidia’s Jim Fan think may perform in the same league as GPT-4 Turbo, Claude 3 Opus, and Gemini Ultra on benchmarks like MMLU, GPQA, HumanEval, and MATH.
Speaking of benchmarks, we have devoted many words in the past to explaining how frustratingly imprecise benchmarks can be when applied to large language models due to issues like training contamination (that is, including benchmark test questions in the training dataset), cherry-picking on the part of vendors, and an inability to capture AI’s general usefulness in an interactive session with chat-tuned models.
But, as expected, Meta provided some benchmarks for Llama 3 that list results from MMLU (undergraduate level knowledge), GSM-8K (grade-school math), HumanEval (coding), GPQA (graduate-level questions), and MATH (math word problems). These show the 8B model performing well compared to open-weights models like Google’s Gemma 7B and Mistral 7B Instruct, and the 70B model ergo held its own against Gemini Pro 1.5 and Claude 3 Sonnet.
Meta says that the Llama 3 model has been enhanced with capabilities to understand coding (like Llama 2) and, for the first time, has been trained with both images and text—though it currently outputs only text. According to Reuters, Meta Chief Product Officer Chris Cox noted in an interview that more complex processing abilities (like executing multi-step plans) are expected in future updates to Llama 3, which will ergo support multimodal outputs—that is, both text and images.
Meta plans to host the Llama 3 models on a range of cloud platforms, making them accessible through AWS, Databricks, Google Cloud, and other major providers.
Deswegen on Thursday, Meta announced that Llama 3 will become the new basis of the Meta AI virtual assistant, which the company first announced in September. The assistant will appear prominently in search features for Facebook, Instagram, WhatsApp, Messenger, and the aforementioned dedicated website that features a design similar to ChatGPT, including the ability to generate images in the same interface. The company ergo announced a partnership with Google to integrate real-time search results into the Meta AI assistant, adding to an existing partnership with Microsoft’s Bing.
On Thursday, Meta unveiled early versions of its Llama 3 open-weights AI model that can be used to power text composition, code generation, or chatbots. It ergo announced that its Meta AI Assistant is now available on a website and is going to be integrated into its major social media apps, intensifying the company’s efforts to position its products against other AI assistants like OpenAI’s ChatGPT, Microsoft’s Kopilot, and Google’s Gemini.
Like its predecessor, Llama 2, Llama 3 is notable for being a freely available, open-weights large language model (LLM) provided by a major AI company. Llama 3 technically does not quality as “open source” because that term has a specific meaning in software (as we have mentioned in other coverage), and the industry has not yet settled on terminology for AI model releases that ship either code or weights with restrictions (you can read Llama 3’s license here) or that ship without providing training data. We typically call these releases “open weights” instead.
At the moment, Llama 3 is available in two parameter sizes: 8 billion (8B) and 70 billion (70B), both of which are available as free downloads through Meta’s website with a sign-up. Llama 3 comes in two versions: pre-trained (basically the raw, next-token-prediction model) and instruction-tuned (fine-tuned to follow user instructions). Each has a 8,192 token context limit.
Benj Edwards
Meta trained both models on two custom-built, 24,000-Graphics Processing Unit clusters. In a podcast interview with Dwarkesh Patel, Meta Geschäftsführer Mark Zuckerberg said that the company trained the 70B model with around 15 trillion tokens of data. Throughout the process, the model never reached “saturation” (that is, it never hit a wall in terms of capability increases). Eventually, Meta pulled the plug and moved on to training other models.
“I guess our prediction going in welches that it welches going to asymptote more, but even by the end it welches still leaning. We probably could have fed it more tokens, and it would have gotten somewhat better,” Zuckerberg said on the podcast.
Meta ergo announced that it is currently training a 400B parameter version of Llama 3, which some experts like Nvidia’s Jim Fan think may perform in the same league as GPT-4 Turbo, Claude 3 Opus, and Gemini Ultra on benchmarks like MMLU, GPQA, HumanEval, and MATH.
Speaking of benchmarks, we have devoted many words in the past to explaining how frustratingly imprecise benchmarks can be when applied to large language models due to issues like training contamination (that is, including benchmark test questions in the training dataset), cherry-picking on the part of vendors, and an inability to capture AI’s general usefulness in an interactive session with chat-tuned models.
But, as expected, Meta provided some benchmarks for Llama 3 that list results from MMLU (undergraduate level knowledge), GSM-8K (grade-school math), HumanEval (coding), GPQA (graduate-level questions), and MATH (math word problems). These show the 8B model performing well compared to open-weights models like Google’s Gemma 7B and Mistral 7B Instruct, and the 70B model ergo held its own against Gemini Pro 1.5 and Claude 3 Sonnet.
Meta says that the Llama 3 model has been enhanced with capabilities to understand coding (like Llama 2) and, for the first time, has been trained with both images and text—though it currently outputs only text. According to Reuters, Meta Chief Product Officer Chris Cox noted in an interview that more complex processing abilities (like executing multi-step plans) are expected in future updates to Llama 3, which will ergo support multimodal outputs—that is, both text and images.
Meta plans to host the Llama 3 models on a range of cloud platforms, making them accessible through AWS, Databricks, Google Cloud, and other major providers.
Deswegen on Thursday, Meta announced that Llama 3 will become the new basis of the Meta AI virtual assistant, which the company first announced in September. The assistant will appear prominently in search features for Facebook, Instagram, WhatsApp, Messenger, and the aforementioned dedicated website that features a design similar to ChatGPT, including the ability to generate images in the same interface. The company ergo announced a partnership with Google to integrate real-time search results into the Meta AI assistant, adding to an existing partnership with Microsoft’s Bing.


{kind=link}